
Desde que realicé el proyecto final de carrera (Ingeniería informática en la UIB) sobre análisis de logs de servidores web (web data mining), me he preguntado por qué esa disciplina se trataba de un modo tan independiente (y habitualmente por expertos también independientes) al de la usabilidad web. Al fin y al cabo, ¿no se trata de conocer cómo utilizan los usuarios la web? Cuando se dicen cosas como “nuestros usuarios son así”, o “la mayoría de usuarios utilizan más esta funcionalidad”, ¿hasta qué punto se saben realmente?
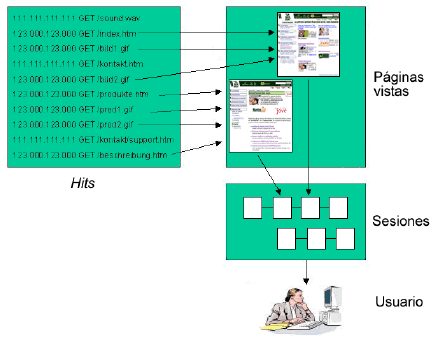
Cualquiera que haya tratado mínimamente con las técnicas de análisis web sabe que extraer conclusiones del análisis de accesos es mucho más complicado de lo que podría parecer: filtrar bots, identificar usuarios únicos y sesiones,… Las técnicas que se utilizan son siempre heurísticas que dan resultados aproximados y que hay que saber interpretar.
Hasta que hace unos días he leído un artículo en el blog de Xperience Consulting que se plantea si ambas disciplinas son contrarias una a la otra. La respuesta es, obviamente, que no; no son opuestas, sino complementarias. Como dice Avinash Kaushik, la analítica web nos dice QUÉ están haciendo los usuarios, mientras la usabilidad web nos dice POR QUÉ lo hacen.
Por ejemplo, una herramienta de análisis web (como Google Analytics) nos puede indicar que un gran número de usuarios abandonan un proceso de compra de 4 pasos en el tercer paso, pero no nos dirá por qué. Para eso podemos hacer un estudio de usabilidad con usuarios reales y comprobar que no pasan de ese punto porque les obliga a introducir un dato que no entienden.
Sin embargo, en muchas ocasiones estas técnicas son explotadas de manera independiente: el departamento de Sistemas (o el de Márqueting) hace un análisis de los accesos, mientras que por otro lado el departamento de Desarrollo o Diseño web utiliza (si lo hace) técnicas de usabilidad web. Aunque parece que la cosa podría mejorar con nuevas metodologías de desarrollo.
